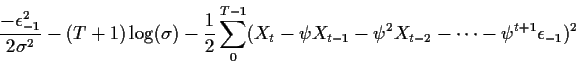Postscript version of these notes
STAT 804: Notes on Lecture 9
Fitting higher order autoregressions
For the model
we will use conditional likelihood again. Let 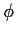 denote the
vector
denote the
vector
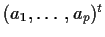 .
Now we condition
on the first p values of X and use
.
Now we condition
on the first p values of X and use
If we estimate 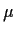 using
using 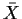 we find that we are trying
to maximize
we find that we are trying
to maximize
To estimate
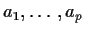 then we merely minimize the sum of squares
then we merely minimize the sum of squares
This is a straightforward regression problem. We regress the response
vector
on the design matrix
An alternative to estimating
by
is to define
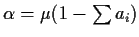 and then recognize that
and then recognize that
is maximized by regressing the vector
on the design matrix
From
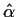 and
and 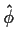 we would get an estimate for
by
we would get an estimate for
by
Notice that if we put
then
and if
then
so that the normal equations (from least squares)
are nearly the Yule-Walker equations again.
Full maximum likelihood
To compute a full mle of
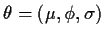 you generally begin by finding preliminary estimates
you generally begin by finding preliminary estimates
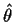 say by one of the conditional likelihood
methods above and then iterate via Newton-Raphson or
some other scheme for numerical maximization of the
log-likelihood.
say by one of the conditional likelihood
methods above and then iterate via Newton-Raphson or
some other scheme for numerical maximization of the
log-likelihood.
Fitting MA(q) models
Here we consider the model with known mean (generally this
will mean we estimate
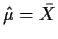 and subtract the mean
from all the observations):
and subtract the mean
from all the observations):
In general X has a
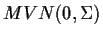 distribution and, letting
distribution and, letting
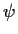 denote the vector of bis we find
denote the vector of bis we find
Here X denotes the column vector of all the data.
As an example consider q=1 so that
It is not so easy to work with the determinant and inverse of matrices
like this. Instead we try to mimic the conditional inference approach
above but with a twist; we now condition on something we haven't observed
--
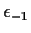 .
.
Notice that
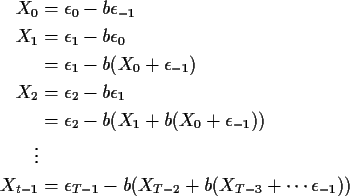
Now imagine that the data were actually
Then the same idea we used for an AR(1) would give
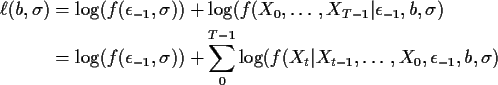
The parameters are listed in the conditions in this formula merely
to indicate which terms depend on which parameters. For
Gaussian 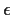 s the terms in this likelihood are squares
as usual (plus logarithms of
s the terms in this likelihood are squares
as usual (plus logarithms of 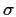 )
leading to
)
leading to
![\begin{align*}\ell(b,\sigma) = &
\frac{-\epsilon_{-1}}{2\sigma^2} - \log(\sigma)...
...2 X_{t-2} - \cdots -\psi^{t+1} \epsilon_{-1})^2+\log(\sigma)\right]
\end{align*}](img38.gif)
We will estimate the parameters by maximizing this function
after getting rid of
somehow.
Method A: Put
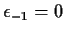 since 0 is
the most probable value and maximize
since 0 is
the most probable value and maximize
Notice that for large T the coefficients of
are close to 0 for most t and the remaining few terms are
negligible relatively to the total.
Method B: Backcasting is the process of
guessing
on the basis of the data; we replace
in the log likelihood by
The problem is that this quantity depends on b and .
We will use the EM algorithm to solve this problem.
The algorithm can be applied when we have (real or imaginary)
missing data. Suppose the data we have is X; some other data
we didn't get is Y and Z=(X,Y). It often happens that we can
think of a Y we didn't observe in such a way that the likelihood
for the whole data set Z would be simple. In that case we can
try to maximize the likelihood for X by following a two step
algorithm first discussed in detail by Dempster, Laid and Rubin.
This algorithm has two steps:
- 1.
- The E or Estimation step. We ``estimate''
the missing data Y by computing
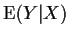 .
Technically,
we are supposed to estimate the likelihood function based on Z.
Factor the density of Z as
.
Technically,
we are supposed to estimate the likelihood function based on Z.
Factor the density of Z as
fZ = fY|XfX
and take logs to get
We actually estimate the log conditional density (which is
a function of 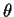 )
by computing
)
by computing
Notice the subscript 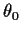 on
on 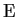 .
This indicates
that you have to know the parameter to compute the conditional
expectation. Notice too that there is another
in the
conditional expectation - the log conditional density has
a parameter in it.
.
This indicates
that you have to know the parameter to compute the conditional
expectation. Notice too that there is another
in the
conditional expectation - the log conditional density has
a parameter in it.
- 2.
- We then maximize our estimate of
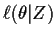 to get
a new value
to get
a new value 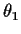 for .
Go back to step 1 with this
replacing
and iterate.
for .
Go back to step 1 with this
replacing
and iterate.
To get started we need a preliminary estimate. Now look at our
problem. In our case the quantity Y is
.
Rather than work with the log-likelihood directly we work with
Y. Our preliminary estimate of Y is 0. We use this value
to estimate
as above getting an estimate .
Then we compute
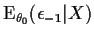 and
replace
in the log-likelihood above by this
conditional expectation. Then iterate. This process of guessing
is called backcasting.
and
replace
in the log-likelihood above by this
conditional expectation. Then iterate. This process of guessing
is called backcasting.
Summary
- The log likelihood based on
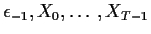 is
is
- Put
in this formula and estimate
by minimizing
where
for
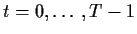 .
.
- Now compute
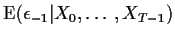 Box, Jenkins and Reinsel presents an algorithm to do so based
on the fact that there are actually two MA representations of
corresponding to a given covariance function (the invertible
one and a non-invertible one). The non-invertible representation
is
Box, Jenkins and Reinsel presents an algorithm to do so based
on the fact that there are actually two MA representations of
corresponding to a given covariance function (the invertible
one and a non-invertible one). The non-invertible representation
is
this
form can be used to carry out the computation of the
conditional expection.
- Iterate, re-estimating
and recomputing the
backcast value of
if needed.
Richard Lockhart
1999-10-12
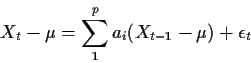
![\begin{displaymath}\ell_c(\phi,\mu,\sigma) = -\frac{1}{2\sigma^2}
\sum_p^{T-1} \...
...-\mu - \sum_1^p a_i(X_{t-i} - \mu)\right]^2
-(T-p)\log(\sigma)
\end{displaymath}](img4.gif)
![\begin{displaymath}-\frac{1}{2\sigma^2}
\sum_p^{T-1} \left[ X_t-\bar{X} - \sum_1^p a_i(X_{t-i} - \bar{X})\right]^2
-(T-p)\log(\sigma)
\end{displaymath}](img7.gif)
![\begin{displaymath}\sum_p^{T-1} \hat\epsilon_t^2 = \sum_p^{T-1} \left[ X_t-\bar{X} - \sum_1^p
a_i(X_{t-i} - \bar{X})\right]^2
\end{displaymath}](img9.gif)
![\begin{displaymath}\left[\begin{array}{c} X_p -\bar{X} \\ \vdots \\ X_{T-1} -\bar{X} \end{array} \right]
\end{displaymath}](img10.gif)
![\begin{displaymath}\left[\begin{array}{ccc}
X_{p-1} -\bar{X}& \cdots & X_0 -\bar...
...{T-2} -\bar{X}& \cdots & X_{T-p-1} -\bar{X}
\end{array}\right]
\end{displaymath}](img11.gif)
![\begin{displaymath}\ell(\alpha,\phi,\sigma) = -\frac{1}{2\sigma^2}
\sum_p^{T-1} ...
...[ X_t-\alpha - \sum_1^p a_iX_{t-i}\right]^2
-(T-p)\log(\sigma)
\end{displaymath}](img13.gif)
![\begin{displaymath}\left[\begin{array}{c} X_p \\ \vdots \\ X_{T-1} \end{array} \right]
\end{displaymath}](img14.gif)
![\begin{displaymath}\left[\begin{array}{ccc}
X_{p-1} & \cdots & X_0
\\
\vdots &...
... & \vdots
\\
X_{T-2} & \cdots & X_{T-p-1}
\end{array}\right]
\end{displaymath}](img15.gif)
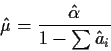
![\begin{displaymath}Z=\left[\begin{array}{ccc}
X_{p-1} -\bar{X}& \cdots & X_0 -\b...
...{T-2} -\bar{X}& \cdots & X_{T-p-1} -\bar{X}
\end{array}\right]
\end{displaymath}](img19.gif)
![\begin{displaymath}Z^tZ \approx T \left[\begin{array}{cccc}
\hat{C}(0) & \hat{C}...
...
\cdots & \cdots & \hat{C}(1) & \hat{C}(0)
\end{array}\right]
\end{displaymath}](img20.gif)
![\begin{displaymath}Y=\left[\begin{array}{c} X_p -\bar{X} \\ \vdots \\ X_{T-1} -\bar{X}
\end{array} \right]
\end{displaymath}](img21.gif)
![\begin{displaymath}Z^tY \approx T \left[\begin{array}{c} \hat{C}(1) \\ \vdots \\ \hat{C}(p)
\end{array}\right]
\end{displaymath}](img22.gif)
![\begin{displaymath}\Sigma = \left[\begin{array}{ccccc}
\sigma^2(1+b_1^2) & -b_1\...
... & \cdots & -b_1\sigma^2& \sigma^2(1+b_1^2)
\end{array}\right]
\end{displaymath}](img31.gif)
![\begin{displaymath}-T\log(\sigma) - \frac{1}{2\sigma^2} \sum_0^{T-1} \left[X_t - \psi X_{t-1}
- \psi^2 X_{t-2} - \cdots -\psi^{t}X_0\right]^2
\end{displaymath}](img40.gif)