attach(`/home/math4/lockhart/teaching/courses/804/datasets')
will make a dataset influenza available. If you type
ls(pos=2)
you will see the data set for this question and the next two.
Alternatively, you can download an ASCII file containing the
data set here. The file can be
used to create an SPlus object using source("influenza.dat").
The data consist of monthly counts of influenza cases over a 9 and a half year period. Fit an ARIMA model to the data.
where the
- (a)
- By full maximum likelihood. (Maximize the joint density of the X's over the
parameters
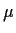 ,
,
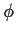 and
and 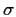 .)
.)
- (b)
- By estimating
by the sample mean and then doing full maximum likelihood
for the model
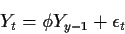
where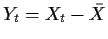 .
.
- (c)
- By estimating
by the sample mean and then doing conditional
maximum likelihood for the previous model.
Remarks: I do not want you to use ar or other built-in S time-series functions to do these but you may want to use them to get starting values for estimates. It is probably easier to do the methods in reverse order, using the results as starting points for iterative solutions.