![]()
![]()
![]()
If plots and/or tests show that the error variances
![]() depend on i there are several standard
approaches to fixing the problem, depending on the nature
of the dependence.
depend on i there are several standard
approaches to fixing the problem, depending on the nature
of the dependence.
This usually arises realistically in the following situations:
If
![\begin{displaymath}\prod_{i=1}^n \frac{\sqrt{w_i}}{\sqrt{2\pi}\sigma}\exp\left[
-\frac{w_i}{2\sigma^2}(Y_i-x_i^T\beta)^2\right]
\end{displaymath}](img12.gif)
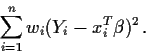
Algebraically it is easy to see how to do the minimization. Rewrite
the quantity to be minimized as
![\begin{displaymath}\sum_{i=1}^n \left[ w_i^{1/2} Y_i - ( w_i^{1/2}x_i)^T\beta\right]^2 \, .
\end{displaymath}](img15.gif)
It is possible to do weighted least squares in SAS fairly easily. As an example we consider using the SENIC data set taking the variance of RISK to be proportional to 1/CENSUS. (Motivation: RISK is an estimated proportion; variance of a Binomial proportion is inversely proportional to the sample size. This makes the weight just CENSUS.
proc reg data=scenic; model Risk = Culture Stay Nratio Chest Facil; weight Census; run ;
EDITED OUTPUT (Complete output)
Dependent Variable: RISK
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Prob>F
Model 5 12876.94280 2575.38856 17.819 0.0001
Error 107 15464.46721 144.52773
C Total 112 28341.41001
Root MSE 12.02197 R-square 0.4544
Dep Mean 4.76215 Adj R-sq 0.4289
C.V. 252.44833
Parameter Estimates
Parameter Standard T for H0:
Variable DF Estimate Error Parameter=0 Prob > |T|
INTERCEP 1 0.468108 0.62393433 0.750 0.4547
CULTURE 1 0.030005 0.00891714 3.365 0.0011
STAY 1 0.237420 0.04444810 5.342 0.0001
NRATIO 1 0.623850 0.34803271 1.793 0.0759
CHEST 1 0.003547 0.00444160 0.799 0.4263
FACIL 1 0.008854 0.00603368 1.467 0.1452
EDITED OUTPUT FOR UNWEIGHTED CASE (Complete
output)
Dependent Variable: RISK
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Prob>F
Model 5 108.32717 21.66543 24.913 0.0001
Error 107 93.05266 0.86965
C Total 112 201.37982
Root MSE 0.93255 R-square 0.5379
Dep Mean 4.35487 Adj R-sq 0.5163
C.V. 21.41399
Parameter Estimates
Parameter Standard T for H0:
Variable DF Estimate Error Parameter=0 Prob > |T|
INTERCEP 1 -0.768043 0.61022741 -1.259 0.2109
CULTURE 1 0.043189 0.00984976 4.385 0.0001
STAY 1 0.233926 0.05741114 4.075 0.0001
NRATIO 1 0.672403 0.29931440 2.246 0.0267
CHEST 1 0.009179 0.00540681 1.698 0.0925
FACIL 1 0.018439 0.00629673 2.928 0.0042
Sometimes the response variable will have a distribution which makes it likely that the errors will be not very normal and that the errors will not be homoscedastic. Typical examples:
Example: For each of the doses
![]() a number of animals
a number of animals
![]() are treated with the corresponding dose of some drug. The
number, Y, dying at dose d is Binomial with parameter h(d).
are treated with the corresponding dose of some drug. The
number, Y, dying at dose d is Binomial with parameter h(d).
The traditional analysis method is to try transformation:
BIGGEST PROBLEM If the model was linear before transformation then it will not be linear after transformation.